Exploring LLM Summarization Techniques to Make Community Board Meetings More Accessible
Written by Seyedeh Farnoosh Hashemi Fesharaki
The Challenge
New York City’s 59 community boards play a crucial role in local democracy, acting as representative bodies of their neighborhoods. Each month, they host public meetings open to anyone in the community, where residents can voice concerns, share ideas, and engage with decisions about housing, transportation, safety, sanitation, zoning, education, and many other issues that directly shape their daily lives.
Yet despite their importance, many New Yorkers are unaware of community boards, have never attended a meeting, or do not realize how much influence these boards have on local governance. Even for those who are interested, the meetings are long—typically running two to three hours—and filled with complex procedural discussions that can be difficult to follow. This creates a significant barrier to civic participation and transparency.
Block Party, an independent civic technology initiative, was created to address this gap. Since the COVID-19 pandemic, when community boards began posting their meetings on YouTube, Block Party has built a growing archive of transcripts—now numbering in the thousands—sourced from automatic captions. Using AI and Natural Language Processing, these transcripts are processed into highlights, summaries, and topic classifications, then shared with the public through a free weekly newsletter and online archive. The goal is to make local democracy accessible and allow residents to stay informed without sitting through hours of meetings.
However, analyzing the transcripts is far from straightforward. Automatic transcripts are often noisy, filled with errors in names, places, and sentence structure. The existing process relies heavily on extractive summarization methods, which simply lifted sentences from transcripts. While this ensured factual fidelity, the results were often disjointed, lacked fluency, and did not provide a coherent narrative of what occurred in the meeting. With the rapid advancement of large language models (LLMs), there was a new opportunity to reimagine this process—but also a need to address the risks of hallucination, coverage gaps, and cost.
The Project
As a Siegel Family Endowment PiTech PhD Impact Fellow, I worked with the Block Party team to improve the quality, clarity, and usability of their meeting summaries. My work focused on designing and testing new summarization pipelines that balanced three priorities:
Faithfulness – ensuring that summaries remained accurate without hallucinating details.
Coverage – capturing the breadth of topics discussed, from community concerns to board decisions.
Fluency and Coherence – producing summaries that read smoothly and were accessible to the general public.
To begin, I explored the performance of both open-source and commercial large language models. I tested established summarization model families such as Flan-T5, BART, and PEGASUS but their small context windows left little room to provide detailed instructions for the model to reliably follow.Given these limitations, I shifted toward more robust, larger models, including GPT-3.5 Turbo and GPT-4o Mini. GPT-4o Mini, in particular, with its larger context window allowed me to input entire transcripts at once, avoiding the need for heavy chunking, and it followed instructions more reliably than other models.
Beyond model selection, I ran extensive prompt engineering experiments to explore different summarization strategies. These were two different ways of prompting the model, each with specific advantages:
Prompting Strategy 1 – Fully Abstractive Summarization: The model was prompted to generate a summary directly from the transcript, focusing on key issues and community concerns It was explicitly instructed not to hallucinate or add unsupported content. This approach produced fluent, coherent summaries that captured a broad range of topics.
Prompting Strategy 2 – Hybrid Anchor Summarization: This approach began with one important sentence taken verbatim from the transcript (such as a resolution or public comment), then built an abstractive narrative around it, while carrying the same instructions. This grounding in the original language improved faithfulness and traceability.
Overall, this project showed that combining large-context LLMs like GPT-4o Mini with carefully designed summarization strategies can produce outputs that are better than prior extractive methods.
Human Evaluation
To systematically assess the quality of different summarization approaches, I designed a survey-based annotation study. The study included five full community board meetings from across Manhattan, the Bronx, Brooklyn, and Queens.
Five Block Party annotators reviewed three different types of summaries for each meeting—generated by the extractive baseline, the fully abstractive prompt, and the hybrid prompt—and rated them on Fluency, Coherence, Faithfulness, and Coverage, using a five-point Likert scale.
The evaluation highlighted clear differences across methods. Both the fully abstractive prompt and the hybrid approach significantly outperformed the extractive baseline on fluency and coherence, while the extractive scored highest in faithfulness. For coverage, the fully abstractive prompt achieved the best and the extractive baseline the worst performance. Overall, abstractive prompting balanced readability and breadth, and hybrid provided stronger grounding in the original text. Nearly all annotators preferred the new strategies, calling the extractive baseline “basically unreadable.”
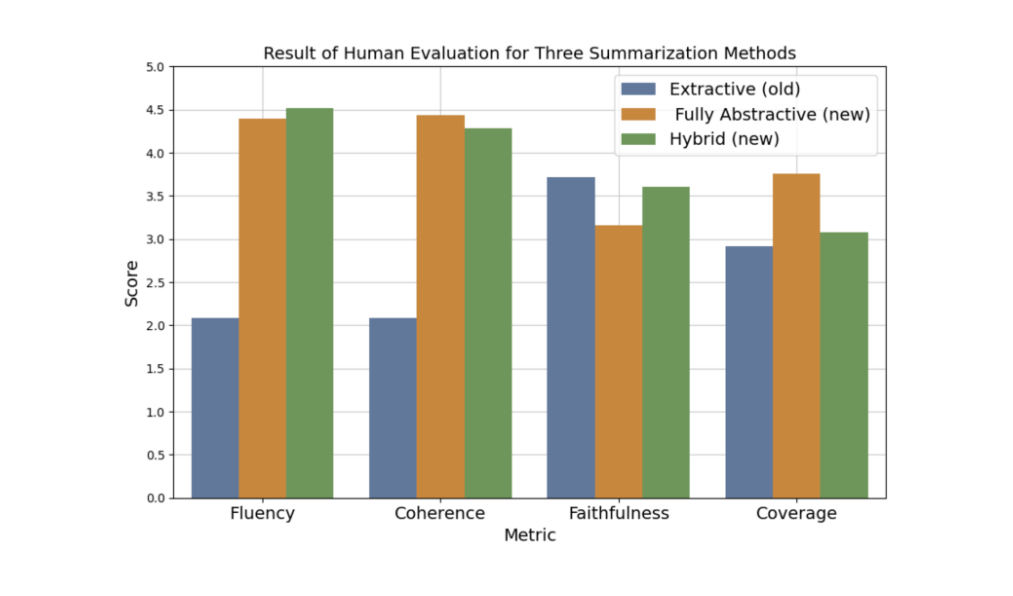
Figure 1: Result of Human Evaluation for Three Summarization Methods

Seyedeh Farnoosh Hashemi Feshararaki
Ph.D. Student, Information Science, Cornell University
Impact and Path Forward
I am deeply grateful for the opportunity to work with the Block Party team through the PiTech Fellowship. Over the summer, I delivered a refined summarization framework that moves beyond extractive methods and incorporates two new prompting strategies which improve fluency, coherence, while remaining faithful to the meeting transcripts. Block Party now plans to apply these approaches across their transcript archive and conduct additional validation.